The Complete Guide to Application Performance Benchmarking
You can usually tell when a team has never benchmarked an app properly. The API “feels fast” on a dev laptop, staging looks fine under a quick smoke test, then


You can usually tell when a team has never benchmarked an app properly. The API “feels fast” on a dev laptop, staging looks fine under a quick smoke test, then

Early stage systems fail loudly. A service crashes, an alert fires, someone rolls back. Mature systems fail quietly, sideways, and often without a single obvious fault. That difference catches even

You can throw faster CPUs at a slow query, but you will still lose if the engine has to touch too many rows to answer something that should have been
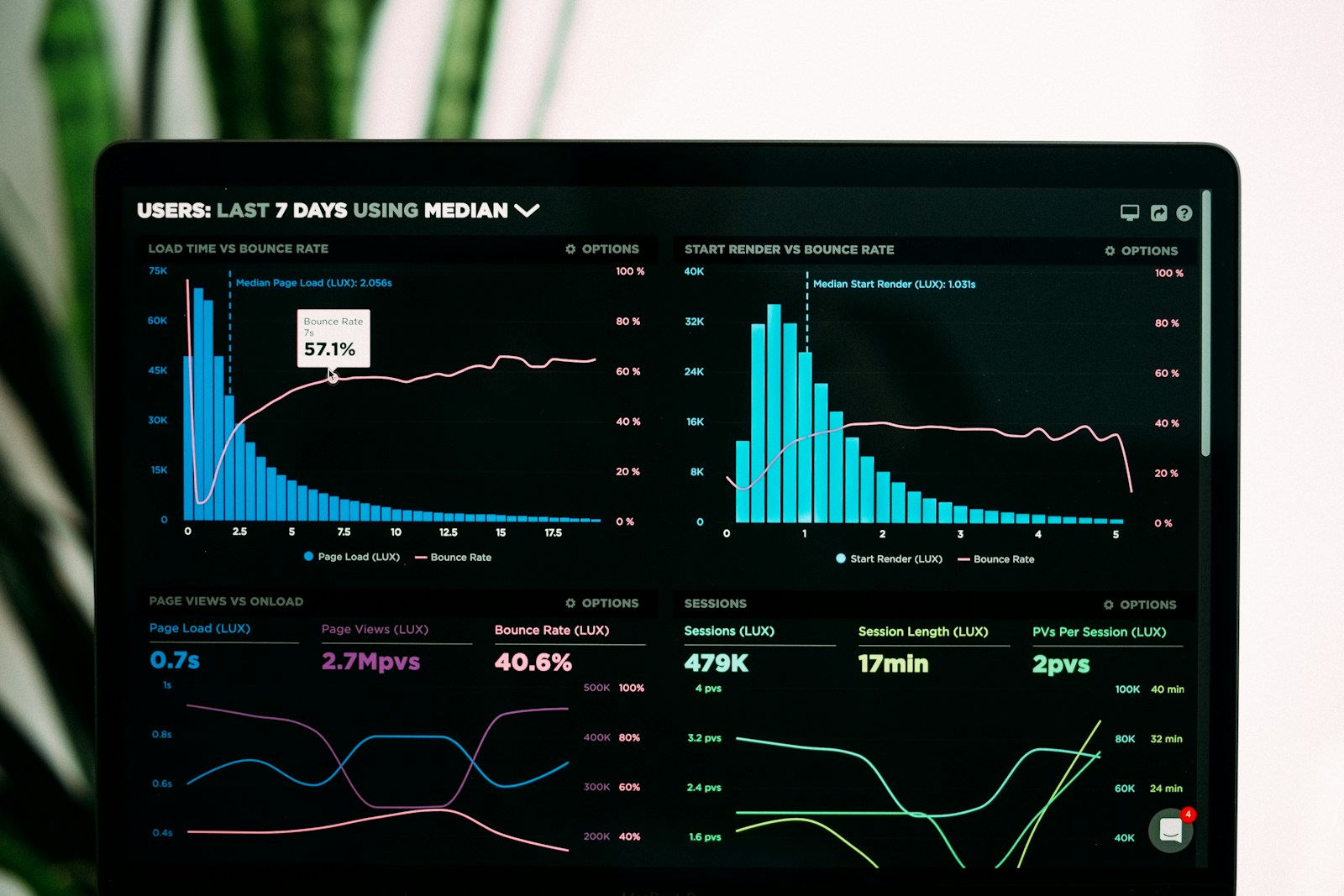
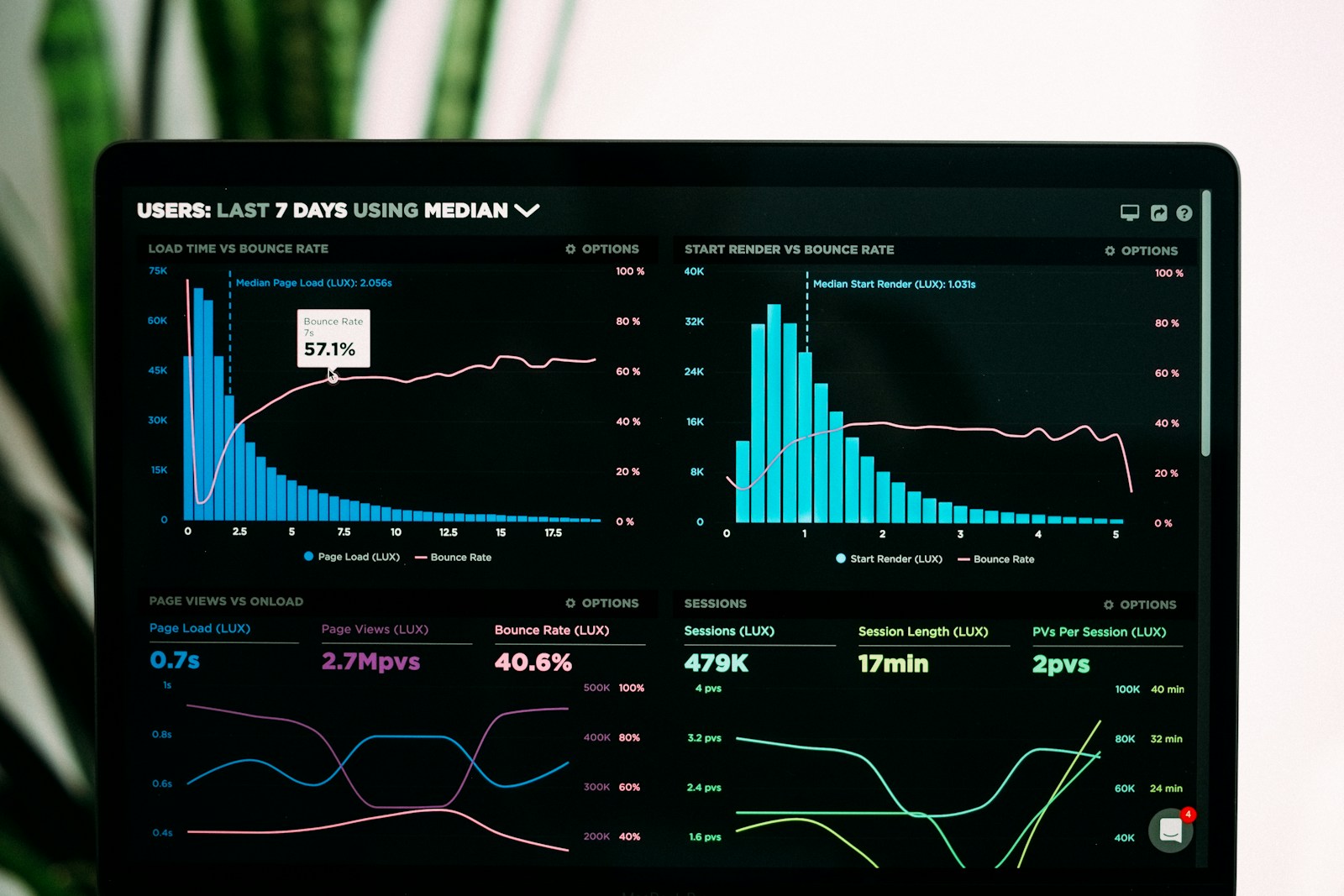
You have probably stared at a wall of green dashboards during an incident and felt uneasy anyway. Latency looks fine. Error rates are flat. Capacity charts say you have headroom.

If you have shipped enough serverless workloads, you know the moment. You deploy a “simple” function. It passes tests, scales effortlessly, and looks clean on paper. Then production teaches you
If you have ever been paged for “elevated error rate” and then spent 45 minutes arguing with dashboards, you already know the dirty secret of distributed systems: the failure is

You do not “add multi-tenancy” to a database. You design a system where a tenant boundary is as real as a network boundary, even though everything might be sharing the

If you have operated a production system long enough, you can probably map your career by production incidents rather than job titles. The first cascading failure you debug at 3

You have been there. Alerts firing, dashboards half red, Slack exploding with theories and hot takes. Someone asks for a rollback while another person is already changing configs in production.